
Un peu plus de six mois après sa création, Kyutai, le laboratoire de recherche de Xavier Niel, dévoile un assistant vocal capable de traiter la voix en temps réel. Moshi ne se concentre pas sur le texte, mais sur la génération de séquences vocales et d’émotions.
En novembre 2023, lors d’un grand show parisien, Xavier Niel et Rodolphe Saadé, en présence de ministres et du Président de la République (en visio), ont dévoilé Kyutai. Un projet ambitieux à but non lucratif qui, comme OpenAI à son origine, vise à créer un laboratoire de recherche pour les chercheurs européens. L’objectif de Kyutai se résume en une phrase : empêcher les cerveaux français de s’enfuir à l’étranger. Kyutai travaille depuis sur l’intelligence artificielle générative, avec pour objectif de concevoir des technologies open source, pour freiner la domination des États-Unis et de la Chine.

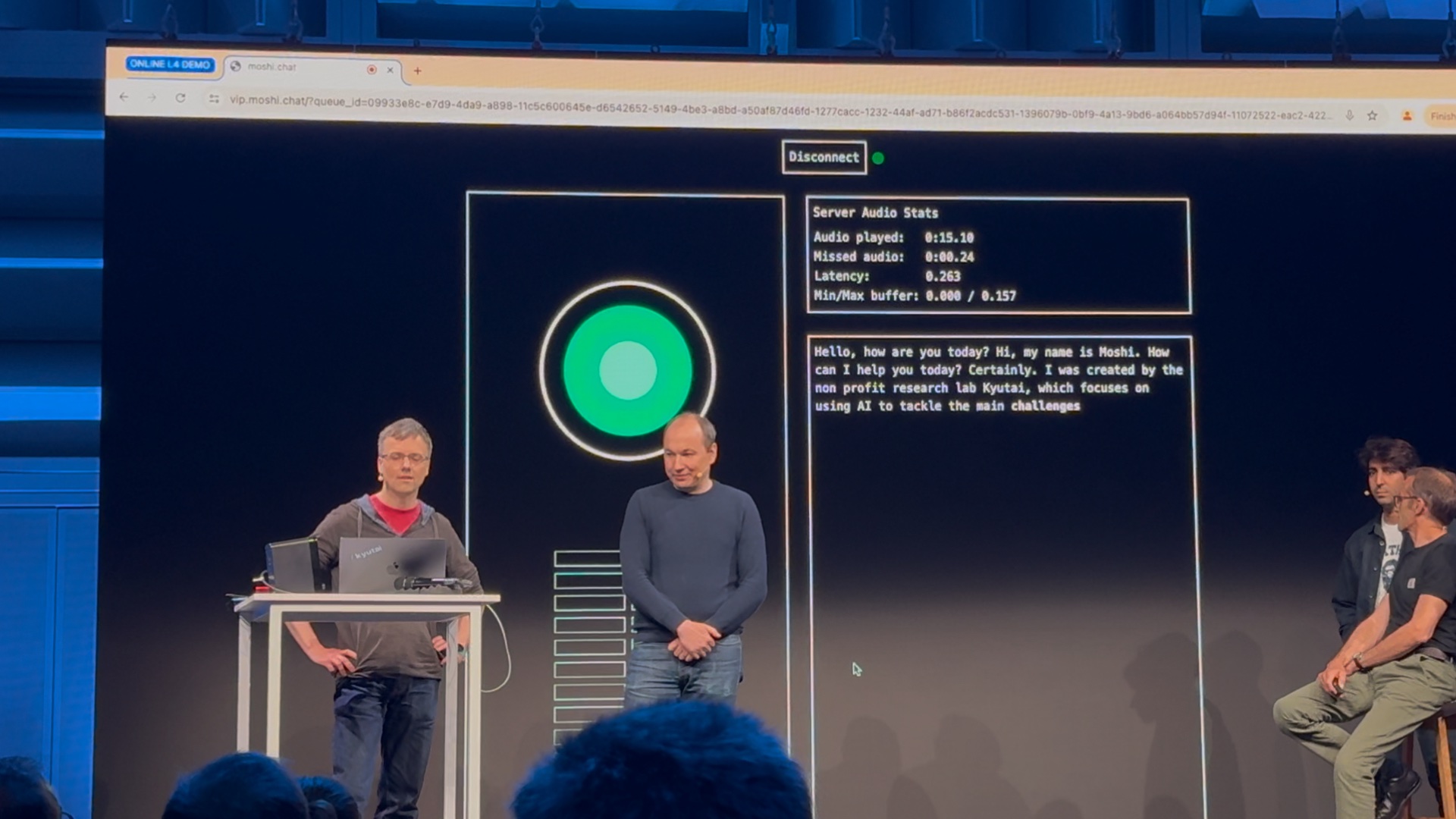
Le 3 juillet 2024, un peu plus de six mois après sa création, Kyutai a dévoilé publiquement le fruit de ses premiers travaux. C’est à l’Ircam, le centre de recherche sur la création musicale, que Kyutai a dévoilé ses premières IA maison. Pour cause, son premier produit s’appelle Moshi et est un assistant vocal ultra sophistiqué capable de traiter la voix en temps réel. Il s’agit d’une réponse directe à GPT-4o (OpenAI) et Astra (Google).
Moshi va vite, très vite
Avec son premier projet, Kyutai fait le pari de ne pas se concentrer sur un chatbot, comme le reste de l’industrie, mais sur un modèle vocal.
Contrairement à la plupart des assistants vocaux, Moshi ne convertit pas une requête vocale en texte pour y répondre. Les travaux de Kyutai visent à la création d’un modèle capable de reconnaître automatiquement du son et de prédire le bruit qui doit arriver ensuite, pour pouvoir arriver à des conversations naturelles. Moshi a été entraîné à partir d’enregistrements d’appels téléphoniques qui ont lieu aux États-Unis entre 1994 et 2002, avec une Française, qui répond au nom d’Alice, qui lui prête sa voix. L’assistant vocal devine ce que vous allez dire et, dès que vous avez fini, répond naturellement. Le temps de latence annoncé est de 160 ms, un record dans l’industrie.
Puisque Moshi traite la voix nativement, il peut reconnaître des émotions. Il est lui-même capable d’en imiter 70, en se basant sur le ton de la conversation. Il peut jouer des jeux de rôle, imiter des accents, chuchoter, blaguer… Comme GPT-4o, le modèle omnimodal d’OpenAI, Moshi donne l’impression de parler à une machine consciente. En revanche, il n’est pas capable de traître une image ou un flux vidéo, il se concentre sur la voix. Une des démos montrées le 3 juillet mettait en scène une interview de Xavier Niel qui, grâce à Moshi, peut continuer à parler avec une imitation virtuelle de sa voix. Impossible de voir la différence.
Évidemment, pour pouvoir improviser, Moshi a besoin d’un modèle de langage pour le texte. Kyutai a mis en place Helium, un LLM avec 7 milliards de paramètres, qui ne parle… qu’anglais pour l’instant. L’entreprise n’a pas encore commencé à travailler sur plusieurs langues, puisqu’elle vise à se faire connaître d’un plus grand nombre de personnes rapidement. Un autre modèle plus petit permet l’usage local de Moshi, sans Internet, sur un ordinateur ou sur un smartphone. Évidemment, il est sujet à un plus grand nombre d’hallucinations.
Puisque Kyutai est un laboratoire open source, tout le monde va pouvoir essayer Moshi dans les prochaines heures. Un « prototype » va être mis en ligne, pour que n’importe qui puisse parler anglais avec l’assistant vocal français.
KABDEL MEDIA


